PUBLICO:Guia optimizacion GPU
Guía de optimización de GPU utilizando mediciones de hardware
Profiling de hardware de GPU y registración de datos
Puede encontrarse mayor detalle de este punto en el ANEXO G, donde se enumeran y califican a todos los contadores de hardware que recopilan las GPUs . Al profundizar en este tema se encontró una gran disparidad en Contadores de Hardware. Por un lado se encuentra diferencias en la información provista por cada fabricante, para el modelo ATI el profilling solo muestra dieciocho Contadores de Hardware mientras que para NVIDIA muestra un total de doscientos diecisiete. Otra gran diferencia es la forma de medir de los Contadores de Hardware, los únicos con información similar son los que miden transferencia de datos y tiempos. Los Contadores de Hardware para ATI solo proseen métricas enfocadas en tres categorías o contextos:
- General: son valoraciones para promedios de distinto tipos de instrucciones/ wavefronts y medición de tiempos.
- Memoria local: Instrucciones o tiempos de acceso a la memoria local (interna al chip GPU).
- Memoria global. Instrucciones o tiempos de acceso a la memoria Global (externa al chip GPU).
Los Contadores de Hardware para NVIDIA se dividen en dos tipos:
Métricas
- Memoria: Se enfocada en las transacciones de memoria local, compartida y global.
- Instrucción: Recolecta información de operaciones para distinto nivel de bifurcación, de uso simple o doble precisión.
- Multiprocesador: Información de los CUDA CORE.
- Caché: Recompila toda la información de las tasas de acceso, acierto y pérdida de memoria cache para los niveles 1 y 2.
- Textura: Informa sobre los datos de acceso a la memoria de textura.
Eventos
- Instrucción: Muestra información en cantidades sobre kerne l, warps e instrucciones.
- Memoria: Diversos accesos a memoria causados por conflictos de bancos, replanificación de instrucciones del warp por accesos repetidos a memoria global (Cantidad de instrucciones de lectura/escritura desde 8 a 128 bits).
- Caché: Detalla la cantidad de solicitudes, pérdidas y escrituras de memoria cache.
- Disparadores genéricos: Definidos por el desarrollador, para recompilar información tantas veces como sea invocado.
La nivelación de mediciones constituyó otra dificultad, para lograr recolectar la información de ambos profilling expresados en la misma magnitud. Ya que NVIDIA expresa las transferencias en bytes, mientras que ATI lo hace en una magnitud acorde a la cantidad de datos, según corresponda. El tiempo es expresado, en NVIDIA en lapsos transcurrido, mientras que ATI, marca el comienzo y fin expresado unidades de tiempo de GPU.
Elaborar relación entre resultados/mediciones de hardware
Las buenas prácticas para optimizar ejecuciones en GPU se enfocan a ciertos casos bien definidos. Cuando los analizamos como punto de partida de la investigación. Encontramos que pueden ser medibles utilizando un único contador de hardware. Por ejemplo “minimizar la sobrecarga de transferencias” al copiar los mismos datos entre CPU al GPU y viceversa. Puede verse con los contadores de hardware WriteSize (en ATI) o gst_transactions (en NVIDIA), que cuantifican las escrituras a memoria global. Otro ejemplo la “maximización del ancho de banda de memoria” se centra en utilizar el orden consecutivo la memoria entre hilos consecutivos, por lo que cada vez que los microinstrucciones del GPU deben ir a buscar a memoria global en lugar de traer solo un byte, trae un conjunto, esta técnica se llama acceso collapsed. Con esto logra que cuando se planifican los hilos, el conjunto (warps o wavefront dependiendo de la tecnología) va a tener disponible la porción de memoria. Si no fuera así, debería hacer accesos a la memoria --de lenta respuesta—por hilo antes de planificarlos en grupo. Este contador de hardware está disponible para NVIDIA l1_global_load_hit. Estos casos marcaron los puntos de partida para generar la guía de optimización. Con distintas pruebas y readaptación de las optimizaciones, se encontró que la clave es relacionar eventos y contadores de hardware. Esta relación forman el conjunto de pautas que conducen a interpretar si la comparación brinda una mejora o no en la búsqueda de optimizaciones. No hay forma de comparar contadores de hardware de ATI y NVIDIA. Lo que se realizo fue buscar contadores que den información expresada en similares parámetros. Luego se aplicaron distintas optimizaciones y se analizó la evolución de contadores seleccionados. La guía se basa en eventos de transferencia en memoria global, dimensionado de kernels y puntos críticos en la ejecución de instrucciones. Los Contadores de Hardware que dan información sobre los accesos a memoria global en ATI son “FetchSize” y “WriteSize”, miden kilobytes transferidos a memoria global. En NVIDIA no hay un contador que los exprese en esas magnitudes, por lo que a estos valores se los obtiene del parámetro de los eventos “cudamemcpy”. La información sobre las dimensiones viene de los contadores de eventos, en NVIDIA para bloque, definido en tres campos (BlockX,BlockY,BlockZ) y en la grilla los siguientes tres campos (GridX,GridY,GridZ). En ATI se define las dimensiones como grupo de trabajo “WorkGroupSize’ y al grupo global “GlobalWorkSize”. A nivel de instrucciones se utilizó el contador de hardware “ipc” en NVIDIA, que indica la cantidad de instrucciones ejecutadas por ciclo.y para ATI un contador de hardware utilizado, que expresa este concepto cómputo-instrucciones en función del tiempo, “VALUBusy” indica el porcentaje de tiempo procesando instrucciones de punto flotante.
Elaboración de guía de optimización de GPU utilizando mediciones de hardware
Formatos que descarten datos ociosos
Los múltiples formatos de representación de matrices dispersas, tienen un doble beneficio. Estas poseen muy pocos elementos distintos de cero (menos al 10%). Los formatos buscan almacenar la información más valiosa minimizando el uso de recursos. Por un lado porque los valores en cero no interfieren en el resultado final del algoritmo, y por otro, se reduce considerablemente el uso de la memoria. En GPU tienen la ventaja que al reducir su consumo de memoria la información a transferir es menor y el acceso a memoria global (lenta), por el hilo kernel también disminuye. Como contra partida en lugar de hacer una sola transferencia (la matriz) se deben transferir los vectores que tienen la información valida. Agrupar transferencias. Bajo ciertas condiciones existe la posibilidad de beneficiarse en transferir entre CPU y GPU una sola vez, en lugar de dividir la transferencia en varias más pequeñas. Se transfiere la misma cantidad de información, lo que varía es la forma (Figura A).
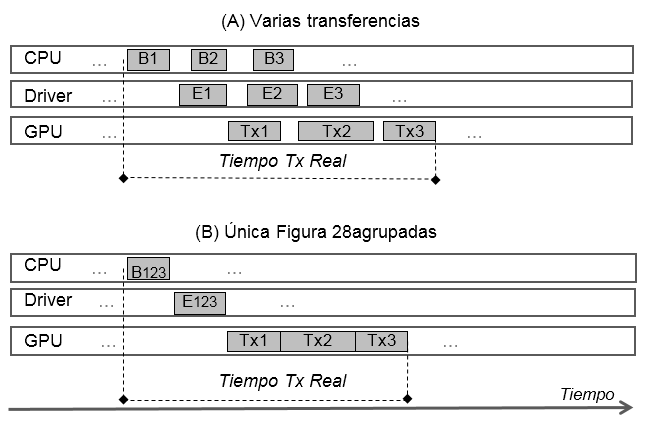 Figura A - Comparación de transferencias simple o seriada.
Figura A - Comparación de transferencias simple o seriada.

Esta situación se da cuando se preparan las pruebas sobre matrices dispersas enfocadas en los formatos de representación. El formato CRS está formado por tres vectores y hay otros como el formato de bloques BSR que se compone de cuatro vectores. Cada vector es transferido en eventos separados (Figura 28 A ). Mientras que existe el formato ELL con dos vectores, (Figura 28 B). Si se agrupan los vectores y se realiza una sola transferencia, se tiene la ventaja que se desprende de la secuencialidad de la CPU, que va invocando a las llamadas a biblioteca (API y Evento). Según sea la carga de la CPU esta puede generar tiempos de demora.
Reutilización de variables globales en cache
Existen casos en el algoritmo sus datos están almacenados en memoria global y necesitan ser accedidas continuamente. Si estos son enviados a memoria interna del kernel, cuando el planificador no disponga de memoria, esta será enviada a la memoria local, que es de acceso lento. Para evitar esta situación se puede usar la memoria textura, que puede ser accedida por el CPU. La memoria de textura posee la particularidad de tener un nivel de memoria caché dentro del core GPU. Sí el dato almacenado en esta memoria solo es accedido por los hilos kernel una vez (Figura B).
 Figura B - Diagrama en bloques de memoria de textura.
Figura B - Diagrama en bloques de memoria de textura.

Relación de lectura en memoria global tendiente a cero
Este parámetro requiere de un conocimiento de las variables que procesa el algoritmo en GPU. Se puede trazar una relación entre los accesos de lectura en memoria global, con la cantidad teóricamente calculada de lo que se espera que use el algoritmo con las propiedades de los datos de entrada. Si esta relación es negativa, significa que se accede menos a memoria global de lo estipulado (el algoritmo no estaría procesando todos los elementos). Si la relación es positiva, se está accediendo a memoria global más de lo esperado (Puede indicar que se está utilizando la memoria global para cuentas intermedias). En cero es el caso ideal.
Relación de escritura en memoria global tendiente a cero
Un caso similar ocurre cuando el algoritmo escribe menos datos que los planificados. En este caso hay que comparar el valor teórico con el obtenido en los Contadores Hardware. Si es negativo el algoritmo se planifica mal, si es positivo está leyendo más cantidad de datos desde memoria global En caso de resultar negativo, puede mejorarse con auxiliares (memoria interna) para que solo se acceda una vez finalizado el algoritmo, desde el auxiliar.
Configuración ajuste minimalista de dimensiones
Por lo analizado en las pruebas de las bibliotecas BLAS. La mala elección del dimensionamiento está fijada por el algoritmo. La cantidad de hilos creados tiene relación con la configuración de dimensiones y a su vez, con la forma en que toma lógicamente esa topología de bloques/grillas en caso de NVIDIA o Grupo Local/Global en ATI. Una forma de evitar el caso anterior y este, de hilos que no impactan en todos los datos del algoritmo, es alinear al tamaño de warp para NVIDIA o wavefront en ATI. En la (Figura C) se sobredimensiona la cantidad de hilos a ejecutar, dando hilos ociosos y desperdicio de recursos.
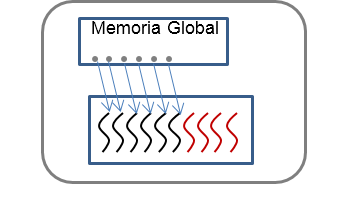 Figura C - Ejemplo de hilos sobre-dimensionados.
Figura C - Ejemplo de hilos sobre-dimensionados.

Operación aritmética en su forma optima
La operación aritmética principal del algoritmo SPMV es la multiplicación de un elemento del vector con todos los elementos de la columna de la matriz. Cada multiplicación se acumula en una variable intermedia, interviniendo las operaciones de multiplicación, suma e igualación. Por simplicidad suele escribirse en seudocódigo como:
Acumulador += Matriz[i][n] * vector[n]
Se ha verificado que aumenta la cantidad de instrucciones por ciclo si se codifica de esta forma.
Acumulador = Acumulador + ( Matriz[i][n] * vector[n] )
Esta mejora no es conmutativa y en cuanto a microinstrucciones del GPU la siguiente expresión da menos rendimiento.
Acumulador = ( Matriz[i][n] * vector[n] ) + Acumulador
La diferencia surge debido a que la GPU está preparada para procesar en forma matemática con un orden definido de operaciones (igualdad – suma – multiplicación).
Mediciones Realizadas
En el siguiente enlace se encuentran las distintas mediciones realizadas durante esta investigacion